

This is the supplement to Chapter 3 of my book, Goals-Based Portfolio Theory, demonstrating the techniques and offering some code examples. If you are reading this having not purchased/read the book, you are missing much of the narrative. You can pick up a copy from Wiley, Amazon.com, or Barnes & Noble.
A fundamental idea in goals-based portfolio theory (though a relatively new one in the literature) is that investors must allocate a limited pool of wealth across many goals, and then allocate that wealth within each goal to a portfolio of investments. Each investor goal, then, will have a unique portfolio of investments.
But the challenge of allocating both within and across goals is not straightforward. In this post I will demonstrate how to accomplish this using R code.
First, we will need some common data to work from. To run this optimization, we will need to following CSV files, which I have reproduced here as tables (but you’ll need to create these CSVs and save them to your working directory).
The model is recursive, so the optimal allocation of wealth to investments within a goal depends on the allocation of wealth to the goal. But the optimal allocation of wealth to a goal depends on the optimal allocation of wealth within that goal.
To solve this recursivity problem, we are going to break the optimization down into two steps. First, we will determine the optimal allocation of investments within a goal for some discrete levels across-goal wealth allocation. In this example, we’ll do 1%-point intervals (so, an optimal portfolio for a 1% allocation of wealth, 2%, 3%, and so on, up to 100%). Second, we will use a simple Monte Carlo method to align the across-goal allocations to the within-goal allocations.
Let’s begin by loading our libraries and building the functions we need.
# Load Dependencies ====================================================
library(ggplot2)
library(RColorBrewer)
library(Rsolnp)
library(nloptr)
# Define Functions =====================================================
# This function will take proposed portfolio weights, forecast volatilities,
# and forecast covariance and return the forecast portfolio volatitliy.
sd.f = function(weight_vector, covar_table){
covar_vector = 0
for(z in 1:length(weight_vector)){
covar_vector[z] = sum(weight_vector * covar_table[,z])
}
return( sqrt( sum( weight_vector * covar_vector) ) )
}
# This function will return the expected portfolio return, given the
# forecasted returns and proposed portfolio weights
mean.f = function(weight_vector, return_vector){
return( sum( weight_vector * return_vector ) )
}
# This function will return the probability of goal achievement, given
# the goal variables, allocation to the goal, expected return of the
# portfolio, and expected volatiltiy of the portfolio
phi.f = function(goal_vector, goal_allocation, pool, mean, sd){
required_return = (goal_vector[2]/(pool * goal_allocation))^(1/goal_vector[3]) - 1
if( goal_allocation * pool >= goal_vector[2]){
return(1)
} else {
return( 1 - pnorm( required_return, mean, sd, lower.tail=TRUE ) )
}
}
# For use in the optimization function later, this is failure probability,
# which we want to minimize.
optim_function = function(weights){
1 - phi.f(goal_vector, allocation, pool,
mean.f(weights, return_vector),
sd.f(weights, covar_table) ) +
100 * (sum(weights) - 1)^2
}
# For use in the optimization function later, this allows the portfolio
# weights to sum to 1.
constraint_function = function(weights){
sum(weights)
}
# For use in mean-variance optimization.
mvu.f = function(weights){
-(mean.f(weights, return_vector) - 0.5 * gamma * sd.f(weights, covariances)^2)
}
# Required return function
r_req.f = function(goal_vector, goal_allocation, pool){
(goal_vector[2]/(goal_allocation * pool))^(1/goal_vector[3]) - 1
}
Next, let’s load our relevant data sets:
# Load & Parse Data ====================================================
n_trials = 10^5 # number of trials to run in MC simulation
# Need to set the directories to the location where you save the files.
# .:.
goal_data_raw = read.csv( "~/Example Goal Details.csv")
capital_market_expectations_raw = read.csv( "~/Capital Market Expectations.csv")
correlations_raw = read.csv( "~/Correlations - Kitchen Sink.csv")
# Record number of potential investments
num_assets = length(capital_market_expectations_raw[,2])
# Record number of goals
num_goals = ncol(goal_data_raw) - 1
# Create vector of expected returns
return_vector = capital_market_expectations_raw[,2]
# Change correlation table to just numbers
correlations = data.frame( correlations_raw[1:15, 2:16] )
# Build a covariance table by merging forecast vol with forecast correlations
# This is an empty matrix to fill with covariances
covariances = matrix(nrow=num_assets, ncol=num_assets)
# Iterate through rows and columns to fill covariance matrix
for(i in 1:num_assets){ # columns
for(j in 1:num_assets){ # rows
covariances[j,i] = capital_market_expectations_raw[i,3] *
capital_market_expectations_raw[j,3] * correlations[j,i]
}
}
# Pull raw goal data and parse into individual goals. Put goal details
# into a vector of the form (value ratio, funding requirement, time horizon)
goal_A = c(goal_data_raw[1,2], goal_data_raw[2,2], goal_data_raw[3,2])
goal_B = c(goal_data_raw[1,3], goal_data_raw[2,3], goal_data_raw[3,3])
goal_C = c(goal_data_raw[1,4], goal_data_raw[2,4], goal_data_raw[3,4])
goal_D = c(goal_data_raw[1,5], goal_data_raw[2,5], goal_data_raw[3,5])
pool = 4654000 # Total pool of wealth
And now we are ready to run our optimization algorithm! As mentioned, we start by finding the optimal investment weights for each level of across-goal allocation. To accomplish this I am using the Rsolnp package’s solnp() function. These optimal allocations are logged to a matrix (a different matrix for each goal) where every row represents a level of across-goal allocation and each column is a potential investment.
Here it is in action:
# STEP 1: Optimal Within-Goal Allocation =============================================
# The first step is to vary the goal allocation and find the optimal
# investment portfolio and its characteristics for each level of across-goal
# allocation. This uses a non-linear optimization engine to find optimal portfolios.
# Start by enumerating the various possible across-goal allocations, (0% to 100%]
goal_allocation = seq(0.01, 1, 0.01)
starting_weights = runif(num_assets,0,1) # Weight seeds to kick-off optim
starting_weights = starting_weights/sum(starting_weights) # Ensure they sum to 1.
# Iterate through each potential goal allocation and find the investment
# weights that deliver the highest probability of goal achievement. Those
# weights will be specific to each goal, so we will log them into a matrix,
# where each row corresponds to a potential goal allocation.
optimal_weights_A = matrix(nrow=length(goal_allocation), ncol=num_assets)
optimal_weights_B = matrix(nrow=length(goal_allocation), ncol=num_assets)
optimal_weights_C = matrix(nrow=length(goal_allocation), ncol=num_assets)
optimal_weights_D = matrix(nrow=length(goal_allocation), ncol=num_assets)
for(i in 1:length(goal_allocation)){
# Use nonlinear optimization function, with constraints
allocation = goal_allocation[i]
covar_table = covariances
# Goal A Optimization
goal_vector = goal_A
if( goal_A[2] <= pool * goal_allocation[i] ){
# If the allocation is enough to fully-fund the goal, force the allocation to all cash.
optimal_weights_A[i,] = c( rep(0, num_assets-1 ), 1 )
} else {
# Otherwise optimize as normal.
result = solnp( starting_weights, # Starting weight values - these are random
optim_function, # Function to minimize - min prob of failure
eqfun = constraint_function, # subject to the constraint function
eqB = 1, # the constraint function must equal 1
LB = rep(0, num_assets), # lower bound values of 0
UB = rep(1, num_assets) ) # upper bound values of 1
optimal_weights_A[i,] = result$pars # Log result
}
# Goal B Optimization, same pattern as Goal A.
goal_vector = goal_B
if( goal_B[2] <= pool * goal_allocation[i] ){
optimal_weights_B[i,] = c( rep(0, num_assets-1), 1 )
} else {
result = solnp( starting_weights,
optim_function,
eqfun = constraint_function,
eqB = 1,
LB = rep(0, num_assets),
UB = rep(1, num_assets) )
optimal_weights_B[i,] = result$pars
}
# Goal C Optimization
goal_vector = goal_C
if( goal_C[2] <= pool * goal_allocation[i] ){
optimal_weights_C[i,] = c( rep(0, num_assets-1), 1 )
} else {
result = solnp( starting_weights,
optim_function,
eqfun = constraint_function,
eqB = 1,
LB = rep(0, num_assets),
UB = rep(1, num_assets) )
optimal_weights_C[i,] = result$pars
}
# Goal D Optimization
goal_vector = goal_D
if( goal_D[2] <= pool * goal_allocation[i] ){
optimal_weights_D[i,] = c( rep(0, num_assets-1), 1 )
} else {
result = solnp( starting_weights,
optim_function,
eqfun = constraint_function,
eqB = 1,
LB = rep(0, num_assets),
UB = rep(1, num_assets) )
optimal_weights_D[i,] = result$pars
}
}
For each goal, we need to find what each level of across-goal allocation yields in goal achievement probability.
# Using the optimal weights for each level of goal allocation, we will
# log the best phis for each level of goal allocation. This will be
# used in the next step to help determine utility.
phi_A = 0
phi_B = 0
phi_C = 0
phi_D = 0
for(i in 1:length(goal_allocation)){
phi_A[i] = phi.f( goal_A, goal_allocation[i], pool,
mean.f(optimal_weights_A[i,], return_vector),
sd.f(optimal_weights_A[i,], covariances) )
phi_B[i] = phi.f( goal_B, goal_allocation[i], pool,
mean.f(optimal_weights_B[i,], return_vector),
sd.f(optimal_weights_B[i,], covariances) )
phi_C[i] = phi.f( goal_C, goal_allocation[i], pool,
mean.f(optimal_weights_C[i,], return_vector),
sd.f(optimal_weights_C[i,], covariances) )
phi_D[i] = phi.f( goal_D, goal_allocation[i], pool,
mean.f(optimal_weights_D[i,], return_vector),
sd.f(optimal_weights_D[i,], covariances) )
}
And, now, we can go about finding the optimal across-goal allocation by plugging the achievement probabilities into the goals-based utility function.
# STEP 2: Optimal Across-Goal Allocation =======================================
# Now that we have the characteristics of the within-goal allocations, we can
# use them to find the best across-goal allocation.
# Begin by building a matrix of simulated goal weights, then return the utility
# for each simulated portfolio.
sim_goal_weights = matrix(ncol=num_goals, nrow=n_trials)
for(i in 1:n_trials){
rand_vector = runif(num_goals, 0, 1)
normalizer = sum(rand_vector)
# Since you cannot have an allocation to a goal of 0, this ensures that the
# minimum allocation is 1.
sim_goal_weights[i,] = ifelse( round( (rand_vector/normalizer)*100, 0 ) < 1,
1,
round( (rand_vector/normalizer)*100 ) )
}
# Find the utility of each trial.
utility = goal_A[1] * phi_A[ sim_goal_weights[,1] ] +
goal_A[1] * goal_B[1] * phi_B[ sim_goal_weights[,2] ] +
goal_A[1] * goal_B[1] * goal_C[1] * phi_C[ sim_goal_weights[,3] ] +
goal_A[1] * goal_B[1] * goal_C[1] * goal_D[1] * phi_D[ sim_goal_weights[,4] ]
# Which simulated portfolio delivered the highest utility
index = which( utility == max(utility) )
# Optimal goal weights
optimal_goal_weights = sim_goal_weights[index,]
We now have our optimal wealth allocation—both across our goals and within each goal! Let’s see our results and generate some visualizations
# Step 3: Return Optimal Subportfolios & Optimal Aggregate Portfolio ===========
# Optimal subportfolio allocations
optimal_subportfolios = matrix( nrow=num_goals, ncol=num_assets )
goals = c("A", "B", "C", "D")
for(i in 1:num_goals){
optimal_subportfolios[i,] =
get( paste("optimal_weights_", goals[i], sep="") )[ optimal_goal_weights[i], ]
}
rownames(optimal_subportfolios) = goals
# Optimal Aggregate Investment Portfolio
optimal_aggregate_portfolio = 0
for(i in 1:num_assets){
optimal_aggregate_portfolio[i] = sum((optimal_goal_weights/100) *
optimal_subportfolios[,i])
}
# Visualize Results ============================================================
# Plot allocation as a function of subportfolio allocation, Goal A
# Data_viz matrix will be long-form.
optimal_weights_A[14:30,12] <- 0 # correct for unstable optim
optimal_weights_A[14:26,13] <- 1.00 # same
asset_names = as.character(capital_market_expectations_raw[,1])
data_viz_1 = data.frame( "Weight" = optimal_weights_A[,1],
"Asset.Name" = rep(asset_names[1], length(optimal_weights_A[,1])),
"Theta" = seq(1, 100, 1) )
for(i in 2:num_assets){
data = data.frame( "Weight" = optimal_weights_A[,i],
"Asset.Name" = rep(asset_names[i], length(optimal_weights_A[,i])),
"Theta" = seq(1, 100, 1) )
data_viz_1 = rbind(data_viz_1, data)
}
# Visualize Goal A's subportfolio allocation as a function of Goal A's across-goal
# allocation.
ggplot( data_viz_1, aes( x=Theta, y=Weight, fill=Asset.Name) )+
geom_area( linetype=1, size=0.5, color="black" )+
annotate('text', x = 8, y = 0.25,
label = 'Angel
Venture')+
annotate('text', x = 35, y = 0.35, label = 'Venture Capital')+
annotate('text', x = 45, y = 0.85,
label = 'Private
Equity')+
annotate('text', x = 70, y = 0.80, label = 'Small Cap')+
annotate('text', x = 71, y = 0.34, label = 'Gold')+
annotate('text', x = 90, y = 0.60, label = 'US Agg
Bond')+
annotate('text', x = 92, y = 0.22, label = 'US
Treasury')+
xlab("Goal Allocation")+
ylab("Investment Weight")+
labs(fill = "Asset" )+
theme_minimal()+
theme( axis.text = element_text(size=14),
legend.text = element_text(size=14),
legend.title = element_text(size=16, face="bold"),
axis.title = element_text(size=16, face="bold") )
# Print the optimal across-goal allocation
optimal_goal_weights
# Print the optimal aggregate investment allocation
optimal_aggregate_portfolio
Which yields the following plot.
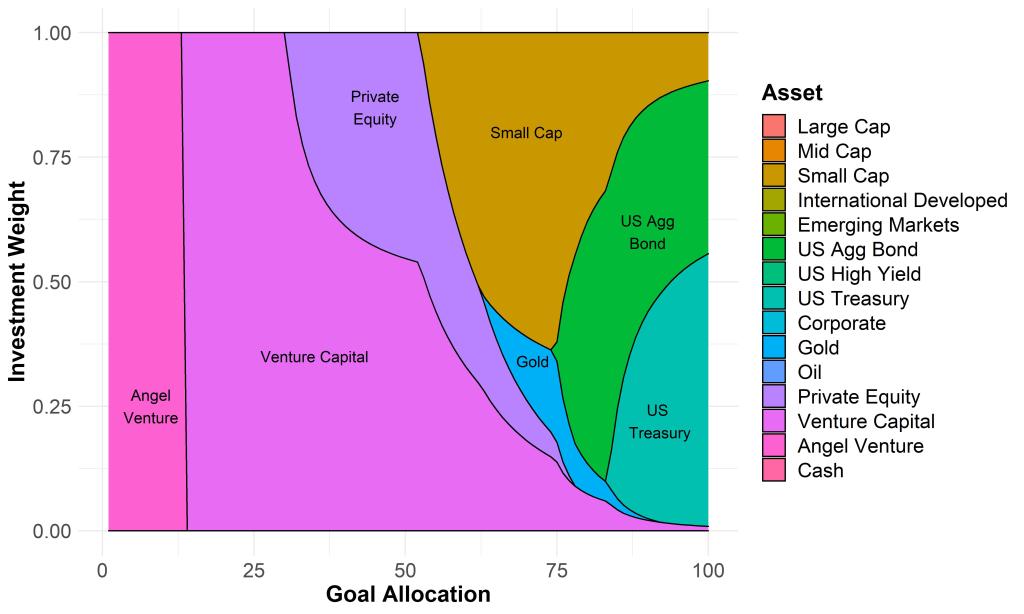
This is the optimal investment allocation for each level of across-goal allocation made to Goal A. Notice how the lottery-like investments take prominence for lower levels of across-goal allocation, and a more traditional portfolio takes over for higher levels of across-goal allocation. This is all different than the mean-variance approach, though I won’t repeat the narrative from the book here.
With Mean-Variance Constraints
Many investors, however, are mean-variance constrained (that is, they want to stay on the efficient frontier). We can use the across-goal allocation method from goals-based portfolio theory but make some adjustments to ensure that we are always on the mean-variance efficient frontier.
Continuing with our code from above (the following code assumes you have run all the code in the previous section), we begin by setting up the efficient frontier and finding the last point on it (we will need to ensure we don’t pass that last point later).
# With Mean-Variance Constraints ===============================================
# We have assumed the no short-sale and no-leverage constraints, as this is
# a common constraint on goals-based investors.
g = seq(60, 1, -1) # vary gamma to build frontier
m = 0 # list to store resultant optimal returns
s = 0 # list to store resultant optimal standard devs
covar_table = covariances
starting_weights = runif(num_assets,0,1) # Weight seeds to kick-off optim
starting_weights = starting_weights/sum(starting_weights) # Ensure they sum to 1.
optimal_weights_mv = data.frame( matrix(nrow=1, ncol=num_assets) )
# Iterate through each level of gamma to find optimal portfolio weights
for(i in 1:length(g)){
gamma =g[i]
result = solnp( starting_weights,
mvu.f,
eqfun = constraint_function,
eqB = 1,
LB = rep(0, num_assets),
UB = rep(1, num_assets) )
optimal_weights_mv = rbind(optimal_weights_mv, result$pars)
m[i] = mean.f(result$pars, return_vector)
s[i] = sd.f(result$pars, covariances)
}
# Visualize MV Efficient Frontier
mv_frontier_data = data.frame( "Volatility" = s,
"Return" = m )
ggplot( mv_frontier_data, aes(x =Volatility, y=Return ) )+
geom_line( size=2, col="dodgerblue" )+
theme( axis.text = element_text(size=14),
legend.text = element_text(size=14),
legend.title = element_text(size=16, face="bold"),
axis.title = element_text(size=16, face="bold") )
# Find last point on the mean-variance efficient frontier, for portfolios with
# less required return than that on offer by the maximum on the frontier, the
# optimal weights are synonymous with mean-variance optimization, otherwise
# the optimization is probability maximization. See Parker (20XX) for discussion.
gamma = 0.01
result = solnp( starting_weights,
mvu.f,
eqfun = constraint_function,
eqB = 1,
LB = rep(0, num_assets),
UB = rep(1, num_assets) )
last_weights = result$pars
last_m = mean.f(result$pars, return_vector)
optimal_weights_mv = rbind(optimal_weights_mv, last_weights)
m[length(g)+1] = mean.f(last_weights, return_vector)
s[length(g)+1] = sd.f(last_weights, covariances)
last_index = nrow(optimal_weights_mv) # row number of last portfolio on
# mv efficient frontier
# Convert means and volatilities to phis, this sets up list to hold them
mv_phi_A = 0
mv_phi_B = 0
mv_phi_C = 0
mv_phi_D = 0
# Store the optimal weights into data frames
optimal_mv_weights_A = data.frame(matrix(nrow=length(goal_allocation), ncol=num_assets))
optimal_mv_weights_B = data.frame(matrix(nrow=length(goal_allocation), ncol=num_assets))
optimal_mv_weights_C = data.frame(matrix(nrow=length(goal_allocation), ncol=num_assets))
optimal_mv_weights_D = data.frame(matrix(nrow=length(goal_allocation), ncol=num_assets))
Then we apply a similar process to the one in the previous section—optimizing the within-goal investment portfolio for each level of across-goal allocation.
# STEP 1: Optimal Within-Goal Allcoation ===============================================
for(i in 1:length(goal_allocation)){
# Iterate through each level of goal allocation:
#
# If the required return is greater than the largest return on
# offer by the MV frontier, then allocation maintains exposure
# to the endpoint of the frontier.
#
# If the required return is less than the largest return on offer
# by the MV frontier, then probability maximization is synonymous
# with mean-variance maximization. See Parker (20XX) for discussion.
# For Goal A
if(r_req.f(goal_A, goal_allocation[i], pool) > last_m){
optimal_mv_weights_A[i,] = last_weights
mv_phi_A[i] = phi.f(goal_A, goal_allocation[i], pool,
mean.f(optimal_weights_mv[last_index,], return_vector),
sd.f(optimal_weights_mv[last_index,], covariances) )
} else {
optimal_mv_weights_A[i,] = optimal_weights_A[i,]
mv_phi_A[i] = phi.f(goal_A, goal_allocation[i], pool,
mean.f(optimal_weights_A[i,], return_vector),
sd.f(optimal_weights_A[i,], covariances) )
}
# Goal B
if(r_req.f(goal_B, goal_allocation[i], pool) > last_m){
optimal_mv_weights_B[i,] = last_weights
mv_phi_B[i] = phi.f(goal_B, goal_allocation[i], pool,
mean.f(optimal_weights_mv[last_index,], return_vector),
sd.f(optimal_weights_mv[last_index,], covariances) )
} else {
optimal_mv_weights_B[i,] = optimal_weights_B[i,]
mv_phi_B[i] = phi.f(goal_B, goal_allocation[i], pool,
mean.f(optimal_weights_B[i,], return_vector),
sd.f(optimal_weights_B[i,], covariances) )
}
# Goal C
if(r_req.f(goal_C, goal_allocation[i], pool) > last_m){
optimal_mv_weights_C[i,] = last_weights
mv_phi_C[i] = phi.f(goal_C, goal_allocation[i], pool,
mean.f(optimal_weights_mv[last_index,], return_vector),
sd.f(optimal_weights_mv[last_index,], covariances) )
} else {
optimal_mv_weights_C[i,] = optimal_weights_C[i,]
mv_phi_C[i] = phi.f(goal_C, goal_allocation[i], pool,
mean.f(optimal_weights_C[i,], return_vector),
sd.f(optimal_weights_C[i,], covariances) )
}
# Goal D
if(r_req.f(goal_D, goal_allocation[i], pool) > last_m){
optimal_mv_weights_D[i,1:num_assets] = last_weights
mv_phi_D[i] = phi.f(goal_D, goal_allocation[i], pool,
mean.f(optimal_weights_mv[last_index,], return_vector),
sd.f(optimal_weights_mv[last_index,], covariances) )
} else {
optimal_mv_weights_D[i,] = optimal_weights_D[i,]
mv_phi_D[i] = phi.f(goal_D, goal_allocation[i], pool,
mean.f(optimal_weights_D[i,], return_vector),
sd.f(optimal_weights_D[i,], covariances) )
}
}
Note the if-else statement in the loop. This tests the result to see if the required return of the portfolio falls outside of the efficient frontier—if it does, we maintain exposure to the last portfolio on the frontier. If it does not, then we proceed with the optimization (the justification for this is discussed in the book).
Next, we proceed with the optimal across-goal allocation using the goals-based utility function, and we can visualize the results.
# STEP 2: Optimal Across-Goal Allcoation ==========================================
# Using Monte Carlo trials in previous section, return utility for each trial of
# simulated goal weight
utility_mv = goal_A[1] * mv_phi_A[ sim_goal_weights[,1] ] +
goal_A[1] * goal_B[1] * mv_phi_B[ sim_goal_weights[,2] ] +
goal_A[1] * goal_B[1] * goal_C[1] * mv_phi_C[ sim_goal_weights[,3] ] +
goal_A[1] * goal_B[1] * goal_C[1] * goal_D[1] * mv_phi_D[ sim_goal_weights[,4] ]
index_mv = which( utility_mv == max(utility_mv) )
# Optimal across-goal allcoation for MV constraints, print the optimal goal weights
# given mean-variance contraints
(optimal_goal_weights_mv = sim_goal_weights[index_mv, ])
# Visualize MV Results ============================================================
# for Goal A
data_viz_2 = data.frame( "Weight" = optimal_mv_weights_A[,1],
"Asset" = rep(asset_names[1], length(optimal_mv_weights_A[,1])),
"Theta" = seq(1, 100, 1) )
for(i in 2:num_assets){
data = data.frame( "Weight" = optimal_mv_weights_A[,i],
"Asset" = rep(asset_names[i], length(optimal_mv_weights_A[,i])),
"Theta" = seq(1, 100, 1) )
data_viz_2 = rbind(data_viz_2, data)
}
ggplot(data_viz_2, aes(x=Theta, y=Weight, fill=Asset) )+
geom_area( linetype=1, size=0.5, color="black" )+
xlab("Goal Allocation")+
ylab("Investment Weight")+
labs(fill = "Asset" )+
theme( axis.text = element_text(size=14),
legend.text = element_text(size=14),
legend.title = element_text(size=16, face="bold"),
axis.title = element_text(size=16, face="bold") )
# Compare probability of achievement for goals-based approach and mean-variance approach,
# For Goal A
data_viz_3 = data.frame( "Theta" = rep( seq(1, 100, 1), 2),
"Phi" = c( phi_A, mv_phi_A ),
"Name" = c( rep( "Goals-Based", 100), rep( "Mean-Variance", 100 ) ) )
ggplot( data_viz_3, aes(x=Theta, y=Phi, lty=Name) )+
geom_line( size=1.5 )+
xlab("Goal Allocation, %")+
ylab("Probability of Achievement")+
labs(color = "")+
theme_minimal()+
theme( axis.text = element_text(size=14),
legend.text = element_text(size=14),
legend.title = element_blank(),
legend.position = 'top',
axis.title = element_text(size=16, face="bold") )
Running the code, you will notice that the lottery-like “Angel Venture” asset is eliminated for mean-variance-constrained investors. This, of course, results in a lower probability of goal achievement for those lower levels of wealth allocation.
In any event, this is an example of how to optimize a goals-based portfolio—both within and across goals.





